
A machine learning project delivering data-driven strategies for movie production companies to select books with high film adaptation potential.
Books have long been a source of inspiration for blockbuster movies, but how do studios decide which ones have cinematic potential? Our team set out to answer this question using machine learning. My team and I analysed over 18,000 book titles to predict their likelihood of becoming high-revenue films, empowering studios with data-driven decision-making.
To ensure an efficient and scalable workflow, we utilized a range of tools for data handling, model training, and evaluation:
We started by diving into the data, cleaning and preprocessing it to ensure its quality. This involved handling invalid ISBNs, standardizing author names, and dealing with missing or abnormal data in book years, user ages, and user countries.
To assess a book's popularity, we needed a metric that went beyond simple average ratings. We considered both the mean rating and the number of people who had rated the book. In our approach, a book's average rating was given higher importance than the number of ratings. Additionally, we recognized that the significance of each additional rating decreases as the total number of ratings increases. For instance, a book with a 10/10 rating from 20 reviewers should be considered more popular than a 10/10 book with only 2 reviews. However, the difference in popularity between a book with 600 ratings and one with 582 ratings is much less pronounced. Our "book popularity score" was designed to capture these nuances.
pi = ri · log20(ni + m)
To identify the most influential factors in a book's success, we used mutual information scores. We looked at features like book author, publication year, number of unique countries reviewing the book, and median reviewer age. Author and number of unique country reviews stood out as key indicators of popularity.
| Feature | Normalized MI Score |
|---|---|
| Book Author | 0.47535 |
| Year of Publication | 0.00749 |
| Number of Unique Countries that Have Reviewed the Book | 0.21448 |
| Median Reviewer Age | 0.00708 |
The normalised mutual information scores between book popularity and various other features of a book.
K-means clustering was used to explore reader demographics, seeking patterns based on book popularity, reader age, and global reach. While initial visualizations didn't reveal distinct clusters, further analysis suggested that reader age was the most significant differentiating factor. Ultimately, our clustering analysis indicated a general reader base across all ages, rather than distinct demographic groups with unique reading habits.
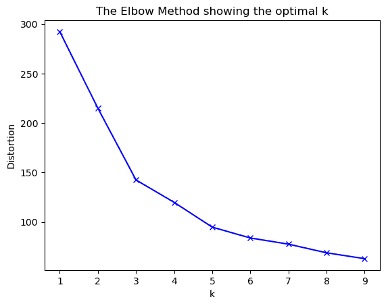
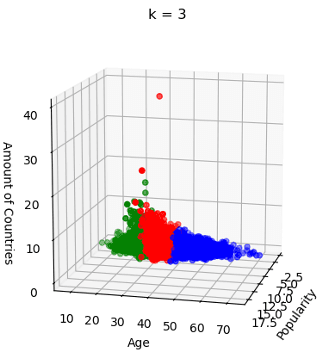
K-Means clustering between 3 features using k = 3 by the Elbow Method
To quantify the relationship between a book’s popularity and its global reach, we used regression analysis. We explored linear, quadratic, square root, logarithmic, and reciprocal regressions, using 5-fold cross-validation to compare their predictive power. Linear regression emerged as the most accurate and precise model. Our analysis confirmed a positive, linear relationship: books with a wider global spread tend to be more popular.
| Regression Technique | MSE cross validation round 1 | MSE cross validation round 2 | MSE cross validation round 3 |
|---|---|---|---|
| Linear | 1.3418 | 1.3193 | 1.3183 |
| Quadratic | 1.3507 | 1.3287 | 1.3229 |
| Square Root | 1.4049 | 1.3798 | 1.3728 |
| Logarithmic | 1.4936 | 1.4640 | 1.4557 |
| Reciprocal | 1.6400 | 1.6071 | 1.5911 |
| MSE cross validation round 4 | MSE cross validation round 5 | Mean MSE | Variance |
|---|---|---|---|
| 1.3878 | 1.3805 | 1.3496 | 0.0009 |
| 1.3963 | 1.6514 | 1.4100 | 0.0152 |
| 1.4665 | 1.3667 | 1.3981 | 0.0013 |
| 1.5772 | 1.4478 | 1.4877 | 0.0022 |
| 1.7530 | 1.5894 | 1.6361 | 0.0037 |
The mean squared error (MSE), average of mean squared errors and variance of mean squared errors for each regression technique over 5 rounds of cross validation
Given the strong link between an author’s popularity and a book's success, we delved deeper into author analysis. We found that highly popular authors often have a larger body of work and a broad global audience. For authors with popularity below 8, popularity tends to increase as they write more books. Authors with outstanding popularities above 8 tend to have “one-hit-wonders.

Regression analysis of author popularity against the number of books that author has written
Based on our analysis, we recommend the following strategies for selecting books with high potential for film adaptation:
By following these data-driven strategies, movie production companies can increase their odds of selecting books that will captivate audiences worldwide and achieve box office success.